
スクレイピングはWebサイトから情報を収集する方法の一つです。これを効率的に行うために、世の中には便利なライブラリやフレームワークがたくさんリリースされています。
しかし、今回は敢えてこの流れに反して、正規表現を使ってスクレイピングをしてみようと思います。これによってスクレイピングの基本を理解できると思います。
# 2020/3/20 記事更新
確認した環境
- OS: Ubuntsu16.04LTS
- Python3.7.4
Webスクレイピングって何?
スクレイピングとは、WebサイトのHTML構造を解析して目的とする情報を取得することです。
以下のサイト様が参考になると思います。
スクレイピングはサーバサイドのプログラミング言語を使って外部サーバへアクセスし、そのコンテンツから自分たちの欲しい情報を引き出す手法です。多くはHTMLを返す場合に使われ、DOMを解析したり正規表現を使ってデータを抜き出します。
引用元サイト:スクレイピングとAPIの違い
正規表現を使ったスクレイピング
スクレイピングは基本的に下記の手順で行います。
例として日本経済新聞のWebサイト(nikkei.com)のトップページの記事タイトルを抽出してみます。
WebサイトのHTMLデータを取得する
requestsモジュール を使って目的のWebサイトのHTMLデータを取得します。
>>> import requests
# 日本経済新聞のWebサイトのURL
>>> url = 'https://www.nikkei.com'
# get()メソッドでHTMLデータを取得
>>> res = requests.get(url)
# 正常に抜き出せたかステータス確認
>>> res.status_code == requests.codes.ok
Truetext属性を使って取得データを確認しました。正常に取得できているようです。
>>> res.text[:250]
'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\r\n\r\n<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja" dir="ltr" id="R1">\r\n<head>\r\n<meta http-equiv="Content-Lang'(参考記事)【Python】 GET・POSTリクエストによるWebデータの取得(Requestsモジュール)
HTMLデータを解析して目的の情報を取得
冒頭にも述べたように、今回は正規表現を使って記事タイトルを抽出します。
(1)取得したい箇所のHTMLスクリプトのパターンを調べる
まず、該当する箇所のHTMLスクリプトを確認します。
Chromeの場合は、ディベロッパーツールを使って簡単に調べることができます。
<ディベロッパーツールでの調べ方>
- ディベロッパーツールを起動する
- 該当部分のHTMLスクリプトを見つける
「Chromeの設定」−「その他のツール(L)」-「デベロッパーツール(D)」を選択(下図の赤枠部)
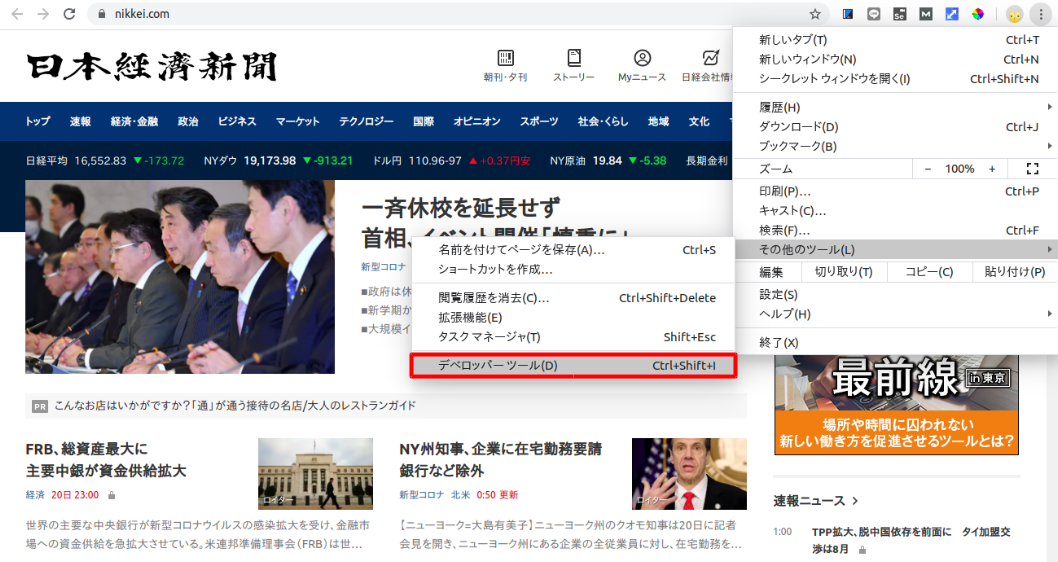
下図の赤枠部のアイコンをクリック後、サイト上の任意箇所をクリックすると、Elementsウインドウに表示されているHTMLスクリプトの該当箇所がハイライトされます。
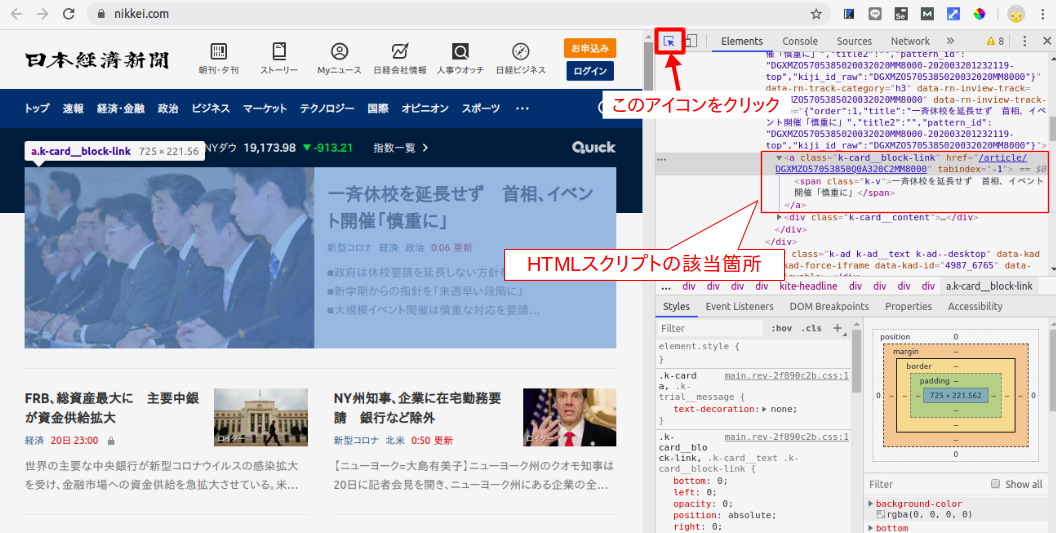
今回は下記のように記述されていました。他の箇所もこれと同じパターンで記述されているようです。
<a class="k-card__block-link" href="/article/DGXMZO57053850Q0A320C2MM8000" tabindex="-1">
<span class="k-v">一斉休校を延長せず 首相、イベント開催「慎重に」</span>
</a>(2)正規表現を使って記事タイトルを抜き出す
HTMLスクリプトのパターンが分かったら、次は正規表現を使って正規表現オブジェクトを生成します。例えば、
# reモジュールをインポート
>>> import re
# 正規表現オブジェクトの生成
>>> regex = re.compile(r'<a class="k-card__block-link".*?><span class="k-v">.+?</span></a>')reモジュールのre.findall() を使って、この正規表現パターンにマッチした箇所(=この場合は記事タイトル)を全て抽出します。
# findall()を使って正規表現にマッチした箇所を全部抽出しリストに格納
>>> subtitles = regex.findall(res.text)
# 更に正規表現を使って、要素のみを抽出
>>> for l in subtitles:
... t = re.search(r'<span.+>(.+)</span>', l).group(1)
... print(t)
# 出力結果
一斉休校を延長せず 首相、イベント開催「慎重に」
ドル、34年ぶり高値に 資金確保に世界が殺到
:
(省略)
:
佐賀銀、人事異動を2週間凍結 継続的な顧客対応優先
北九州のぬか炊き 地味でも滋味、魚や肉を煮付けうまく抽出できたようです。
尚、上記をまとめたコード例をこちらに挙げておりますので、興味があればご参照ください。
Webサイトへのアクセス時の応答エラー対応なども追記しています。
(参考記事)
【Python】正規表現 reモジュールの使いかたの基本
【Python】文字列を検索する(in演算子、find、正規表現)
まとめ
正規表現を使ったスクレイピングのやり方についてまとめました。
今回は、目的の要素を的確に抽出するための「正規表現パターン」を作るにあたってかなり試行錯誤しました。余計な要素まで抽出されてしまったり、逆に必要な要素が抽出できていなかったり・・・
こういった苦労を解決してくれるのが、BeautifulSoupのような便利なライブラリです。
使い方についてはこちらの記事(【Python】BeautifulSoupを使ったWebスクレイピング )で解説していますので、併せてご参照ください!

