Seleniumは、ブラウザをコマンドを使って遠隔操作することのできるツールです。元々はWebアプリの試験の自動化が主な用途のようですが、スクレイピングにも用いられるようです。また、このツールはPythonから制御することも出来ます。本記事では、PythonからSeleniumモジュールを使ってchromeブラウザを直接制御する方法についてまとめます。
Seleniumって何?
まずはSelenium IDEを使って試してみます。
Selenium IDEはChromeやFirefoxのプラグインで、ブラウザの操作履歴を記録し、それを後で自動で再現できます。Webアプリのテストを自動化するなどの用途に使われるそうです。
ここではChromeをベースに、以下の手順でSelenim IDEを動かしてみます。
<手順>
- Selenium IDEをインストールします
Chrome web storeから、Selenium IDEをChromeの拡張機能に追加します。
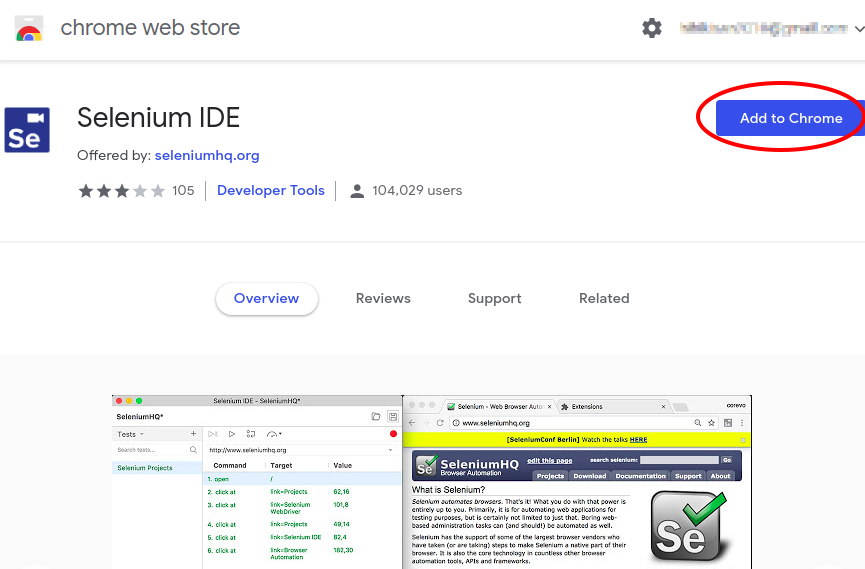
- Selenium IDEを起動します。
Chromeブラウザのアドレスバーの右横のselenium IDEアイコン![]() をクリックしてselenium IDE起動します。
をクリックしてselenium IDE起動します。
- Base URLを設定します。
Selenium IDEウィンドウで、
-
-
- “Base URL”欄: 表示させるWebサイトのURL
- “command”欄: ”open”
-
をそれぞれ入力します。以下の例はGoogleのトップページ(https://www.google.co.jp)を開く処理です。
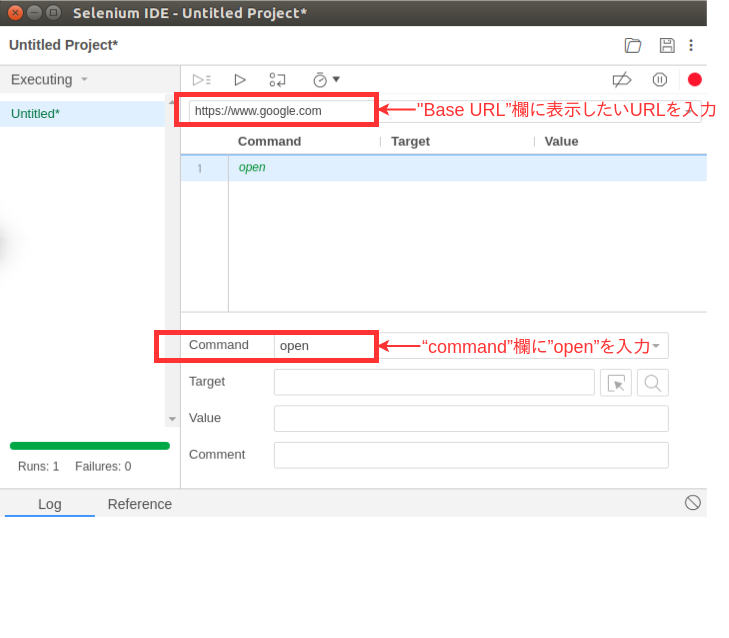
※ ここで試しに ”Run current Test” ボタンを押してみます。すると、ブラウザが立ち上がり、Googleのトップページが自動で表示されるはずです。
ボタンを押してみます。すると、ブラウザが立ち上がり、Googleのトップページが自動で表示されるはずです。
- ユーザ操作をSelenium IDEに記録します。
画面右側の”start recording” を押して記録を開始します。
を押して記録を開始します。
ボタンが になれば録画中を示します。
になれば録画中を示します。
次に、実際にブラウザで以下の操作を行い、操作を記録してみましょう。
-
-
- google検索窓に、”python”と入力
- 検索ボタンを押す
- 検索結果から、python.orgをクリック
-
ブラウザで操作をするたびに、Selenim IDEにコマンドが追加されていくのが見えると思います。
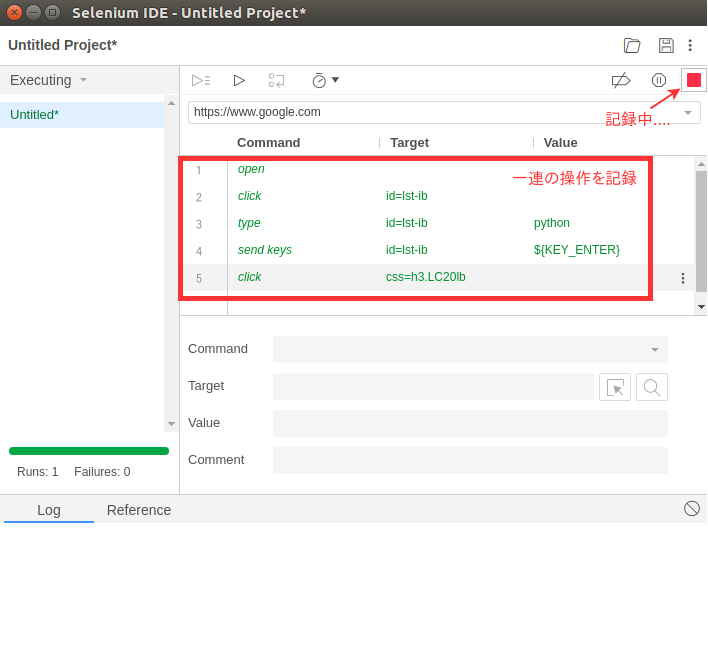
尚、前手順で記載したopenコマンドが一番最初のステップに来ているかどうか確認し、なければドラッグ&ドロップ等で修正しておきます。
また、ここで必要に応じて上記で作成した操作手順(テストケースと呼ぶらしいです)を保存しておきます。
- 作成したテストケースを実行します。
“Run current Test”ボタンを押します。すると、上記で記録した操作が自動的に実行されます。
ちなみに、Seleniumで開いたブラウザは非常に重たいので、何個も立ち上げるとメモリが不足しPCが遅くなるかもしれません。。。
このように、SeleniumはWebブラウザの動作を自動で実行してくれるツールです。
(ここからやっと今回の記事の本題です)今回は、このSeleniumをPythonから制御しスクレイピングを行う方法についてまとめます。
PythonからSeleniumを動かす
確認した環境
- OS: Ubuntu16.04LTS
- Python 3.7.0@Anaconda
- Browser: Chrome : 69.0.3497.100(Official Build) (64 ビット)
Seleniumのインストール
Seleniumを使うには、SeleniumモジュールとWebdriverのインストールが必要です。
(1)Seleniumモジュールのインストール
Anaconda環境では以下のコマンドでインストールできます。
$ conda install selenium(2)Webdriverのインストール
Seleniumは、Firefox、Edge,InternetExplore, Chrome, Safari、その他世の中の多くのブラウザに対応していますので、使うブラウザに合ったものをインストールします。
今回はChromeを使いますので、こちらからダウンロードします。
ダウンロードしたら、PATHの通るディレクトリ(/usr/local/bin)にコピーしておきます。
$ wget https://chromedriver.storage.googleapis.com/2.42/chromedriver_linux64.zip
$ unzip ./chromedriver_linux64.zip
Archive: ./chromedriver_linux64.zip
inflating: chromedriver
$ sudo cp chromedriver /usr/local/bin/他のブラウザについては公式サイトの下の方に記載がありますのでご参照ください。
Pythonからブラウザを起動する
それでは、まずは日本経済新聞のWebサイト(https://www.nikkei.net)を例にして、トップページの記事を抽出する処理を考えてみます。
まずはブラウザを起動し目的のWebサイトを開きます。手順は以下です。
- webdriver.Chrome()を呼び出し、WebDriverオブジェクトを生成
- get()メソッドに目的のWebサイトのURL(ここでは”https://www.nikkei.com”)を設定
コード例を以下に示します。
>>> from selenium import webdriver
# Chromeの起動/Webdriverオブジェクトの生成
>>> browser = webdriver.Chrome()
# URLを開く
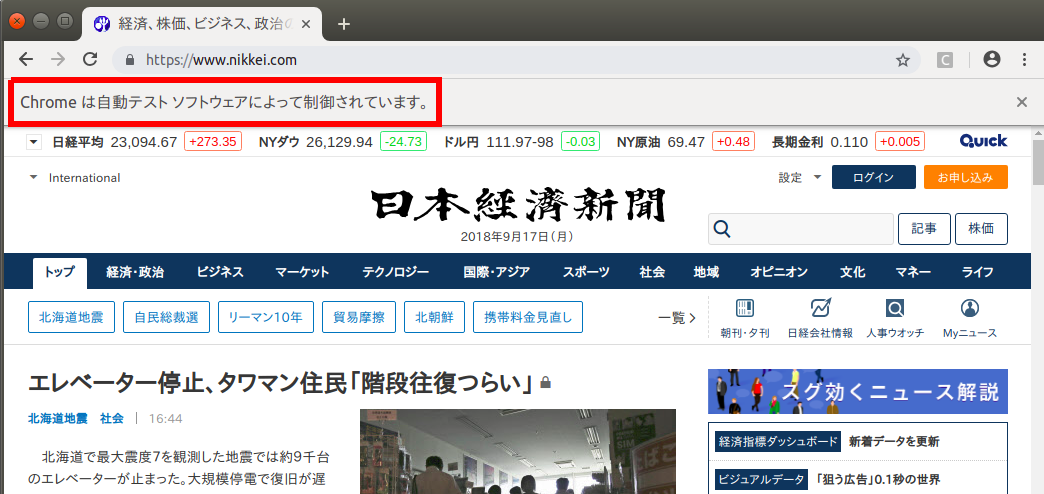
>>> browser.get('https://www.nikkei.com/')上記のコードを実行すると、ブラウザが起動して目的のWebサイトが開きます。画面に「Chromeは自動テストソフトウエアによって制御されています」という表示が出ているのが解ると思います。
要素を抽出する
要素を抽出するにあたっては、タグやname属性を指定するなど色々な方法があります。ここでは、CSSセレクタを指定する方法を使ってみたいと思います。
find_elements_by_css_selector()メソッドは引数で指定したCSSセレクタにマッチした全ての要素を、一つのWebElementオブジェクトとして返します。
<参考> CSSセレクタはChromeの場合はディベロッパーモードから簡単に取得できます。やり方は以下の記事で紹介していますのでご参照ください。
[Python] BeautifulSoupを使ったWebスクレイピング – CSSセレクタをselect()メソッドに渡す
WebElementオブジェクトはさまざま属性(プロパテイ)を持ち、DOM要素を表すことができます。
例えば、text属性を指定することで、要素の内部テキストを抽出できます。
コード例を以下に示します。
# WebElementオブジェクトを生成
>>> elems = browser.find_elements_by_css_selector('h3 > a > span.m-miM09_titleL')
# text属性で要素を取得
>>> for e in elems:
... e.text
...
'上海株、3年10カ月ぶり安値\u3000アジア株も軒並み安'
'苫東厚真1号機18日にも再稼働\u3000損傷少なく大幅前倒し'
'自動運転の開発、量子コンピューター活用広がる'
'海自潜水艦が南シナ海で訓練\u3000初の公表、中国けん制'
'中国、対米協議拒否も\u3000第3弾関税表明なら'
'共働きのカギは男性\u3000家事育児、ノルマは現状の2倍'
'「二日酔い運転」に注意\u3000飲酒事故の3割は朝~正午'その他の抽出方法
Seleniumは多くのメソッドや属性(プロパティ)を提供しており、色々な方法で要素を取得できます。詳細はこちらのサイトが詳しいですが、ここでは主なものを挙げます。
これらの使い方を具体的な例を使って見ていきたいと思います。
そこで、別の例としてGoogle financeから日経平均とダウ平均の数値を取得する処理を考えます。
尚、下表における項番(No)はその下のコード例のコメントの番号に相当しています。
- WebDriverメソッド
| No | 説明 | メソッド |
|---|---|---|
| 1 | リンクテキストの一部がマッチした要素を取得 | find_element_by_partial_link_text(link_text) |
| 3 | CSS selectorによって要素を取得 | find_element_by_css_selector(css_selector) |
| 4 | xpathによって要素を取得 | find_element_by_xpath(xpath) |
| 7 | name属性から要素を取得 | find_element_by_name(name) |
- WebElementオブジェクトのメソッド、プロパティ
| 項 | 説明 | プロパティ |
|---|---|---|
| 2 | 指定された属性または要素のプロパティを取得 | get_attribute(name) |
| 5 | テキストをクリア | clear() |
| 6 | 現在フォーカスされている要素にキーを送信します。 | send_keys(*keys_to_send) |
| 8 | フォームを送信 | submit() |
以下、コード例
from selenium import webdriver
url = 'https://www.google.com/finance'
b = webdriver.Chrome()
b.get(url)
# ➀リンクテキストの一部がマッチした要素を取得
a = b.find_element_by_partial_link_text('Nikkei 225')
# ②指定された属性または要素のプロパティを取得
url = a.get_attribute('href')
b.get(url)
print("Nikkei225:")
# CSSセレクタを定義
selector_sp = "#knowledge-finance-wholepage__entity-summary > div > g-card-section > div > g-card-section > div.gsrt > span:nth-child(1) > span > span"
# ③ CSS selectorによって要素を抽出
n225_sp = b.find_element_by_css_selector(selector_sp)
print("- Price:", n225_sp.text)
# Xpathを定義
xpath_date = '//*[@id="knowledge-finance-wholepage__entity-summary"]/div/g-card-section/div/g-card-section/div[2]/span[1]/span[2]'
# ④xpathによって要素を取得
n225_sp_date = b.find_element_by_xpath(xpath_date)
print("- Update:", n225_sp_date.text)
SEARCH_KEY = "INDEXDJX: .DJI"
# CSS selectorによって要素を抽出
search = b.find_element_by_css_selector("#lst-ib")
# ⑤テキストをクリア
search.clear()
# ⑥現在フォーカスされている要素にキーを送信
search.send_keys(SEARCH_KEY)
# ⑦name属性から要素を取得
frm = b.find_element_by_name("btnG")
# ⑧フォームを送信
frm.submit()
print("DOW JONES:")
# 以下、④共通
xpath_dow = '//*[@id="knowledge-finance-wholepage__entity-summary"]/div/g-card-section/div/g-card-section/div[1]/span[1]/span/span'
dow_sp = b.find_element_by_xpath(xpath_dow)
print("- Price:", dow_sp.text)
xpath_date = '//*[@id="knowledge-finance-wholepage__entity-summary"]/div/g-card-section/div/g-card-section/div[2]/span[1]/span[2]'
dow_date = b.find_element_by_xpath(xpath_date)
print("- Update:", dow_date.text)出力結果を以下に示します。想定通り抽出できました。
Nikkei225:
- Price: 23,869.93
- Update: 9月21日 15:15 JST ·
DOW JONES:
- Price: 26,743.50
- Update: 9月21日 16:54 GMT-4 ·まとめ
今回は、PythonからSeleniumを使ってブラウザを直接制御することでスクレイピングを行う方法についてまとめました。BeautifulSoupを使った方法もありますが、抽出対象によって使い分けていくと効率的にできそうですね。

