
Requestsモジュールは、PythonでHTTP通信を行うための3rdParty製のライブラリです。本記事では、このモジュールを使ってGET/POSTリスクエストを送信し、Webサイトのデータを取得する方法についてまとめます。
# 2019/1/4 更新
確認した環境
- OS: Ubuntu16.04LTS
- Python3.7.0 @Anadonda
Requestsモジュールのインストール
このモジュールはPythonの標準ライブラリでないので、環境によっては新規にインストールが必要かもしれません。その場合は公式サイトを参照してインストールを行います。
筆者はAnacondaを使っていますので、下記コマンドでインストールしました。
~$ conda install requestsHTTP通信の概要
まず、HTTP通信の概要とリクエストメソッドについて、概要を簡単に記載します。
WebブラウザでWebページを開いたりすると、WebブラウザとWebサーバの間でデータのやり取りが行われます。このやり取りはHTTPというプロトコルに基づいて行われます。
- Webブラウザは、開きたいWebページのアドレスをWebサーバに要求(リクエスト)します。
- Webサーバは、ブラウザからのリクエストを受けて色々な処理をし、ブラウザへ回答(レスポンス)します。
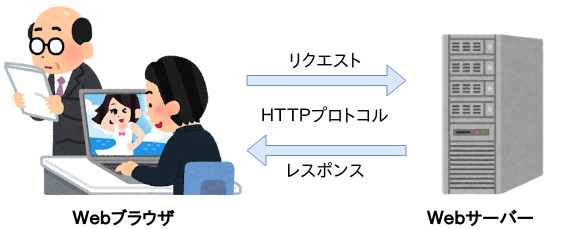
HTTPではいくつかのリクエストメソッドが定義されていますが、ここではGETメソッドとPOSTメソッドについて以下に挙げます。
- GETメソッド
- 特定リソース(例えば指定されたURL)からデータを取得する為に使います。
- クエリ文字列は、GETリクエストのURLに含まれて送信されます。
- POSTメソッド
- データをサーバに送信して、リソースを作成/更新する為に使われます。
- データはHTTPリクエストのbodyに含まれます。
詳細については、例えば以下のサイトが参考になると思います。
- https://tools.ietf.org/html/rfc7231#section-4.3 (HTTPの仕様書)
- https://developer.mozilla.org/ja/docs/Web/HTTP/Methods
- https://qiita.com/Sekky0905/items/dff3d0da059d6f5bfabf
- https://teratail.com/questions/11271
GETメソッドを用いたWebサイトのデータ取得
requests.get()メソッドを使うとWebサイトのデータを取得できます。
引数に取得したいWebサイトのURLを指定すると、サーバからレスポンス(Responseオブジェクト)が返ります。レスポンスの中身を読み出すには、text属性を使います。
以下にコード例を記載します。
# GETリクエストによるResponseオブジェクトの生成
>>>> res = requests.get('https://hibiki-press.tech/learn_prog/')
# text属性でレスポンスの内容を読み出す
>>> res.text[:100]
'<!DOCTYPE html>\n<html lang="ja" class="no-js no-svg">\n<head>\n<meta charset="UTF-8">\n<meta name="view'GETメソッドでパラメータを送信する
Web APIへのアクセスやログイン処理をする際など、URLに何らかのパラメータを付与してリクエストを送信する場合は、URLの後にクエリ文字(”?パラメータ1&パラメータ2&…”)を付けて以下のように指定します。
>>> requests.get('http://example.com?param1=value1¶m2=value2')
尚、requests.get()メソッドはこれらのクエリ文字をキーワード引数paramsを使って指定することができます。すなわち、上記は以下のように書けます。
>>> info = {'param1':'value1', 'param2':'value2'}
>>> requests.get('http://example.com', params=info}
以下に、MediaWiki API(Wikipediaの検索API)を使った例を示します。
import requests
# URLの設定
url = "http://ja.wikipedia.org/w/api.php"
# パラメータの設定
param = { "format": "json",
"action": "query",
"prop": "revisions",
"titles": "日本酒",
"rvprop": "content",
"rvparse":""}
# Responseオブジェクトの生成
res = requests.get(url, params=param)
# レスポンスの中身(最初の200文字)
>>> res.text[:200]
'{"batchcomplete":"","warnings":{"main":{"*":"Subscribe to the mediawiki-api-announce mailing list at <https://lists.wikimedia.org/mailman/listinfo/mediawiki-api-announce> for notice of API deprecation'
# URLの確認
>>> res.url
'https://ja.wikipedia.org/w/api.php?format=json&action=query&prop=revisions&titles=%E6%97%A5%E6%9C%AC%E9%85%92&rvprop=content&rvparse='※urlのクエリ文字の中身が、URLエンコード(application/x-www-form-urlencodedだと思います)されていることに注意。requestsモジュールが自動的にエンコードしてくれているようです。
POSTメソッドでデータを送信する
requests.post()メソッドを使うとPOSTメソッドでリクエスト送信ができます。使い方はget()メソッドと同様で、URLを引数に指定します。また、パラメータはキーワード引数dataに設定します。
※この引数は辞書型、タプルのリスト、バイト列、file-likeオブジェクトを取ります
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)また、Requestsモジュールのversion2.4.2以降はパラメータとしてキーワード引数jsonを設定できます。これは、JSONデータを直接設定したい場合に用いられます。
>>> url = 'https://api.github.com/some/endpoint'
>>> payload = {'some': 'data'}
>>> r = requests.post(url, json=payload)パラメータの設定は、dataを使うか、jsonを使うか?
色々調べましたが、結局のところアクセスする先の「API仕様による」のではないかと思います。(当たり前かも・・・)
- APIがデータの送受信にJSON形式を要求していれば、キーワード引数jsonを用いる。これにより、dict型もjson形式に変換され、且つリクエストヘッダのContent-Typeもapplication/jsonに自動的に変更されます。
- または、json.dump()関数でdict型データをJSON形式に変換してキーワード引数dataに設定する。この場合は、リクエストヘッダheadersのContent-Typeをapplication/jsonに指定しておく必要があります。
# 一旦文字列へ変換してdataへ設定
>>> r = requests.post(url, data=json.dumps(payload))- APIが辞書形式のデータで問題なければ、dataパラメータを用いる
※間違いなどあればご指摘いただけると助かります。
取得したデータをファイルに保存する
得られたデータをファイルに保存するには、通常のファイル書き込みの手順と同様にopen()関数を用います。
下記は、お天気Webサービス(Livedoor Weather Web Service / LWWS)(http://weather.livedoor.com/weather_hacks/webservice)へアクセスする例です。
>>> import requests
# お天気Webサービス(Livedoor Weather Web Service / LWWS)のAPIへアクセス
>>> info = {'city':140010}
>>> r = requests.get('http://weather.livedoor.com/forecast/webservice/json/v1', params = info)
# 取得したレスポンスデータをファイルに保存する
>>> with open('savefile.txt', 'w') as f:
... f.write(r.text)
... Responseオブジェクトの属性いろいろ
Responseオブジェクトが対応している主な属性(text属性以外)を以下に挙げます。
- status_code属性
HTTPステータスコード(404、200など)を返します。
# 正常にアクセスできる場合
>>> res = requests.get('https://hibiki-press.tech/learn_prog/')
# ステータスコードのチェック
>>> res.status_code
200
# 存在しないページにアクセスした場合
>>> no_exist = requests.get('https://hibiki-press.tech/no_exist/')
# ステータスコードのチェック
>>> no_exist.status_code
404また、Requestsモジュールは整数値のステータスコードをエラー名に置き換えたrequests.codesオブジェクトを定義しており、例えば、ステータスコード:200は、“requests.codes.ok”と表せます。これとstatus_codeの出力値を比較することで、Webサイトに正常にアクセスできたかどうかチェックできます。
# 正常にアクセスできた場合
>>> res.status_code == requests.codes.ok
True
# 存在しないページにアクセスした場合
>>> no_exist.status_code == requests.codes.ok
False- ok属性
ステータスコードが200〜400の場合にTrueを返します。クライアントエラーまたはサーバーエラーをチェックするために使われます。尚、これはstatus_code=200であることを確認するものではないので注意です。
# ステータスコードが200〜400の場合
>>> res.ok
True
# ステータスコードが400〜の場合
>>> no_exist.ok
False- reason属性
“Not Found” や “OK”など、HTTPステータスの理由を文字列で示します。
# HTTPステータスの理由
>>> res.reason
'OK'
>>> no_exist.reason
'Not Found'- url属性
最終的にアクセスしたURLを返します。リダイレクトが行われたかどうかを確認できます。
# 最終的にアクセスしたURL
>>> res.url
'https://hibiki-press.tech/learn_prog/'エラー処理について
404 Not Foundなどのアクセスエラーが発生した場合にもプログラムを正常に継続動作させるには、エラーチェックの仕組みを入れる必要があります。
やり方はいくつかあると思いますが、ここでは、raise_for_status()を使って例外を発生させる方法について試してみたいと思います。
raise_for_status()は、Responseオブジェクトの属性の一つです。requsts.get()の結果、HTTPErrorが発生していた場合にHTTPErrorを発生させます。例えば、
# 正常にアクセスできた場合
>>> res = requests.get('https://hibiki-press.tech/learn_prog/')
# HTTPErrorが発生していないので、Noneを返す
>>> res.raise_for_status()
# 存在しないページにアクセスした場合、、
>>> no_exist = requests.get('https://hibiki-press.tech/no_exist/')
# HTTPErrorが送出される
>>> no_exist.raise_for_status()
Traceback (most recent call last):
File "", line 1, in
File "/home/hibikisan/anaconda3/envs/python3.7/lib/python3.7/site-packages/requests/models.py", line 939, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://hibiki-press.tech/learn_prog/no_exist/これを利用して、サイトにアクセスした際にアクセスエラーが発生したとしても、プログラムを止めずに継続させることができます。例えば、以下のコードは指定したURLにアクセス出来なかった場合にエラーメッセージを表示するものです。
import requests
def url_check(url):
try:
res = requests.get(url)
res.raise_for_status()
# リクエストが成功したらOKを表示
print('OK')
except requests.RequestException as e:
# エラーが発生したら、その内容を表示
print(e)実行結果は以下です。
# 存在しないページの場合
>>> url_check('https://hibiki-press.tech/no_exist')
404 Client Error: Not Found for url: https://hibiki-press.tech/learn_prog/no_exist
#ドメインが存在しない場合
>>> url_check('https://hibiki-press.xxx')
HTTPSConnectionPool(host='hibiki-press.xxx', port=443): Max retries exceeded with url: / (Caused by NewConnectionError(': Failed to establish a new connection: [Errno -2] Name or service not known',))
# 正常にアクセスできた場合
url_check('https://hibiki-press.tech/learn_prog')
OKアクセスエラーが発生してもプログラムが予期しないエラーによって停止せず、処理を継続できていることが確認出来ると思います。
まとめ
今回は、Requestsモジュールを用いたHTTPリクエストにより、Webサイトのデータを取得方法についてまとめました。Webスクレイピングや、Web-APIへのアクセスなど応用範囲は広そうですので、使いこなしていきたいです。


コメント
[…] GET、POSTによるWebデータの取得 […]
[…] 【Python】 GET・POSTリクエストによるWebデータの取得(Requestsモジュール)【Python】BeautifulSoupを使ってテーブルをスクレイピング10分で理解する Beautiful Soup […]