
BeautifulSoupは、Webサイトをスクレイピングしてデータを取得する際に便利なライブラリです。正規表現を使ってデータを取得する方法もありますが、正規表現パターンの構築の難しさが懸念としてありました。本記事では、こんな心配を解決してくれる(はずの)ライブラリの基本的な使い方についてまとめます。
確認した環境
Ubuntsu16.04LTS
Python3.7.0BeautifulSoupのインストール
BeautifulSoupモジュールがまだ自分の環境になければ、インストールします。Anaconda環境を使っていれば以下コマンドでインストールできます。
$ conda install beautifulsoup4ちなみに、このモジュールの呼び方は、「びゅーてぃふるすーぷ」です。念の為。
BeautifulSoupによるHTML解析
まずは、以下のHTMLデータ(sample.html)を例に使ってまとめて行きます。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>Agatha Christiee's Novels</title>
</head>
<body>
<center>
<h1>Agatha Christiee</h1>
</center>
<div class="booklist">
<h1>BOOK LIST</h1>
<h2 id="poirot" class="john">The Mysterious Affair at Styles</h2>
<h2 id="tommy" class="dodd">The Secret Adversary</h2>
<h2 id="poirot" class="dodd">Murder on the Links</h2>
<h2 id="race" class="dodd">The Man in the Brown Suit</h2>
<h2 id="others" class="dodd">The Secret of Chimneys</h2>
</div>
<input type="button" value="Logout" onclick="location.href='logout.php'">
</body>
</html> BeautifulSoupオブジェクトの生成
HTMLドキュメントをBeautifulSoup()メソッドに渡してBeautifulSoupオブジェクトを生成します。
# bs4モジュールをインポート
>>> import bs4
# htmlファイルを開く
>>> htmlfile = open('./sample.html')
# BeautifulSoupオブジェクトを生成
>>> soup = bs4.BeautifulSoup(htmlfile, 'lxml')第一引数に解析したいHTMLドキュメント、第二引数にparser(解析器)を設定します。
公式ドキュメントによるとparserは‘lxml’が速くておすすめとのことなので、ここでもそれを使います。但し、Python標準ライブラリでないので、環境によっては新規インストールが必要かもしれません。その場合は以下でインストールできます。
~$ conda install lxml尚、実際のWebサイトからデータを読み込んでBeautifulSoupオブジェクトを生成する方法については後述します。
Tagオブジェクトを生成し目的の要素を抽出する
BeautifuleSoupを使って目的の要素を抽出するには以下の3つの方法があります。
以下にそれぞれについてまとめます。
- タグを指定する方法
先に生成したBeautifulSoupオブジェクトに対してHTMLタグを指定し、Tagオブジェクトを生成することで各タグ要素を抽出できます。文章よりも以下の例を参照したほうが早いかもしれません。
#タグを指定することで、Tagオブジェクトを生成する
# titleタグ
>>> soup.title
<title>Agatha Christiee's Novels</title>
# bodyタグ > 1 > centerタグ > h1タグ
>>> soup.body.center.h1
<h1>Agatha Christiee</h1>
# h2タグ
>>> soup.h2
<h2 class="john" id="poirot">The Mysterious Affair at Styles</h2>
# 2つめのh2タグ
>>> soup.h2.next_sibling.next_sibling
<h2 class="dodd" id="tommy">The Secret Adversary</h2>-
- CSSセレクタをselect()メソッドに渡す
CSSセレクタをselect()メソッドに渡すと、Tagオブジェクトを要素としたリストが返ります。それぞれのTagオブジェクトについてstring属性を指定することで目的のタグ要素が抽出できます。
# h2要素且つclass=dodd属性を抽出する
>>> titles = soup.select('h2.dodd')
# 返り値はリスト
>>> type(titles)
<class 'list'>
# リストの各要素はTagオブジェクト
>>> type(titles[0])
<class 'bs4.element.Tag'>タグ要素を抽出してみます。
# h2要素を全て抽出
>>> soup.select("h2")
[<h2 class="john" id="poirot">The Mysterious Affair at Styles</h2>,
<h2 class="dodd" id="tommy">The Secret Adversary</h2>,
<h2 class="dodd" id="poirot">Murder on the Links</h2>,
<h2 class="dodd" id="race">The Man in the Brown Suit</h2>,
<h2 class="dodd" id="others">The Secret of Chimneys</h2>]
# h2要素、id属性が"tommy"の要素を抽出
>>> soup.select("h2#tommy")
[<h2 class="dodd" id="tommy">The Secret Adversary</h2>]
# h2要素、class属性が"john"の要素を抽出
>>> soup.select("h2.john")
[<h2 class="john" id="poirot">The Mysterious Affair at Styles</h2>]
# > を使うことでタグの親子関係を表す
>>> soup.select("div > h2#race")
[<h2 class="dodd" id="race">The Man in the Brown Suit</h2>]
# h2要素且つclass=dodd属性の要素の内容を全て取得します
>>> titles = soup.select("h2.dodd")
>>> for l in titles:
... print(l.string)
...
The Secret Adversary
Murder on the Links
The Man in the Brown Suit
The Secret of Chimneys尚、CSSセレクタの詳細についてはこちらのサイトが詳しいのでご参考にどうぞ。
-
- find_all()メソッドでタグと属性を指定する
find_all()メソッドを使うと、BeautifulSoupオブジェクト全体を検索して、マッチしたタグ要素を全て返します。このメソッドは以下の書式で使われます。
find_all(name, attrs, recursive, string, limit, **kwargs)第一引数nameはタグ名、第二引数にclassやid等の属性を指定します。返り値はResultSetオブジェクトと呼ばれ、Tagオブジェクトを要素としたリストに似たオブジェクトです。目的のタグ要素は、それぞれの要素についてstring属性を確認することで得られます。
# h2要素を全て検索する
>>> l = soup.find_all('h2')
# 返り値はResultSetオブジェクト
>>> type(l)
<class 'bs4.element.ResultSet'>
# 各要素はTagオブジェクト
>>> type(l[0])
<class 'bs4.element.Tag'>要素を抽出する際の例を以下に示します。
尚、class属性を指定する際は、”class=”ではなく、”class_=”とすることに注意です。
# タグ名を指定
>>> soup.find_all("h2")
[<h2 class="john" id="poirot">The Mysterious Affair at Styles</h2>,
<h2 class="dodd" id="tommy">The Secret Adversary</h2>,
<h2 class="dodd" id="poirot">Murder on the Links</h2>,
<h2 class="dodd" id="race">The Man in the Brown Suit</h2>,
<h2 class="dodd" id="others">The Secret of Chimneys</h2>]
# id属性を指定
>>> soup.find_all(id="tommy")
[<h2 class="dodd" id="tommy">The Secret Adversary</h2>]
# class属性を指定 (class_と書くことに注意)
>>> soup.find_all(class_="john")
[<h2 class="john" id="poirot">The Mysterious Affair at Styles</h2>]
# 正規表現も使えます
>>> import re
>>> soup.find_all(class_=re.compile('dd'))
[<h2 class="dodd" id="tommy">The Secret Adversary</h2>,
<h2 class="dodd" id="poirot">Murder on the Links</h2>,
<h2 class="dodd" id="race">The Man in the Brown Suit</h2>]
# タグ名とclass属性を同時に指定
>>> soup.find_all('h2', class_=re.compile('dd'))
[<h2 class="dodd" id="tommy">The Secret Adversary</h2>,
<h2 class="dodd" id="poirot">Murder on the Links</h2>,
<h2 class="dodd" id="race">The Man in the Brown Suit</h2>]
# h2要素且つclass=dodd属性の要素の内容を全て取得します
>>> tites = soup.find_all("h2", class_="dodd")
>>> for l in titles:
... print(l.string)
...
The Secret Adversary
Murder on the Links
The Man in the Brown Suit
The Secret of Chimneys以上が、BeautifulSoupの使い方の基本です。次に、これらを実際のWebサイトに適用して見たいと思います。
実際のWebサイトから情報を取得してみよう
前回と同じ様に、日本経済新聞のWebサイト(nikkei.com)からトップページの記事のタイトルを抽出します。
まず、requestsモジュールを使ってWebサイトのHTMLデータを取得し、text属性でドキュメント化したものを使ってBeautifulSoupオブジェクトを生成します。
# WebサイトのHTMlデータの取得
>>> import requests
>>>
>>> url = 'https://www.nikkei.com'
>>> res = requests.get(url)
# BeautifulSoupオブジェクトを生成
>>> import bs4
>>> soup = bs4.BeautifulSoup(res.text, 'lxml')次に、トップページの記事タイトルを抽出します。CSSセレクタを使う(select()関数)方法と、find_all()を使う方法の両方を試します。
- CSSセレクタを使う(select()関数)方法
CSSセレクタは、Chromeの場合はディベロッパーツールを使って確認出来ます。
ディベロッパーツールの起動の仕方は、こちらの記事でもまとめています。ご参照ください。
ツール上で取得目的のHTML記述にカーソルを当て右クリック→「Copy」→「Copy selector」とクリックすると、CSSセレクタが得られます。(下図の赤枠部)
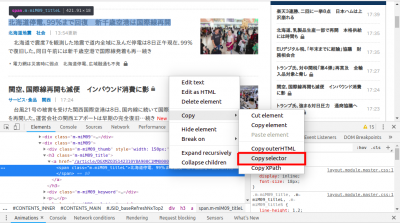
今回スクレイピングの対象としているページの記事タイトルのCSSセレクタを上記の方法で幾つか調べると、記事の場所によって異なるCSSセレクタが得られました。
# 記事の場所によって異なるCSSセレクタが得られた
#JSID_baseRefreshNxTop2 > div.m-miM07 > h3 > a > span
#JSID_baseRefreshNxTop2 > div:nth-child(3) > h3 > a > span
#JSID_baseRefreshNxTop2 > div.m-miM10 > div:nth-child(1) > h3 > a > spanこれらCSSセレクタ−のパターンを全て網羅してselect()関数に渡しても良いですが、スマートなやり方ではありません。そこで、これらをまとめて抽出するために少し工夫が必要です。つまり
div > h3 > a > span[class$='_titleL']とすれば目的としているトップページの記事タイトルを全て取得できそうです。
早速select()メソッドに引き渡してみます。
>>> titles_01 = soup.select("div > h3 > a > span[class$='_titleL']")
>>> for l in titles_01:
... print(l.string)
...
# 実行結果
訪日客倍増に「空」の壁 操縦士不足・成田拡張も限界
:
(省略)
:
NTT、IT事業再編 コム・データなど統括新会社- find_all()を使う
find_all()を使う方法についても試してみます。今回目的としている記事タイトルのHTML構造を見てみると、<span>タグとclass属性に特徴がありそうです。そこで、下記のように引数を指定してみました。ここで特徴的なのは、class属性の設定に正規表現を使っている点です。このようにfind_all()関数では、正規表現を使ってclass属性を表現できます。
尚、結果は上記と同じ内容が得られています。
>>> titles_02 = soup.find_all('span', class_ = re.compile('m-mi\w{3}_titleL'))
>>> for l in titles_02:
... print(l.string)
...
訪日客倍増に「空」の壁 操縦士不足・成田拡張も限界
:
(省略)
:
NTT、IT事業再編 コム・データなど統括新会社以上が、BeautifulSoupを使ったスクレイピングの基本となります。
CSSセレクタはブラウザのディベロッパーツールを使えば簡単に取得できますが、今回のようにそのまま使うには適さない値を返す場合があります。こういった場合は得られた内容をベースに簡略化や他との共通化を図るなど、ひと工夫が必要です。
また抽出したい箇所のHTML構造を分析して、効率よく抽出できるようカット&トライでいろいろ試してみることも必要だと思います。
まとめ
- BeautifulSoupを使ったWebスクレイピングの基本についてまとめました。
- 抽出したい箇所のHTML構造を分析して、適切なタグやCSSセレクタを見極めることが重要。

コメント
[…] こういった苦労を解決してくれるのが、BeautifulSoupのような便利なライブラリです。使い方についてはこちらの記事(【Python】BeautifulSoupを使ったWebスクレイピング )で解説していますので、よければご参照ください! […]